Video Based Human Motion Prediction
Human motion prediction is the process of anticipating the motion of humans based on observed data. This can vary from predicting the direction and speed of a person to characteristics like joint position prediction. It has a wide range of applications ranging from robotics – specifically human robot collaboration and collision avoidance as well as applications in sports and human computer interaction.
Deep learning has proven to be a powerful tool for predicting human motion and in this blog we will explore a step by step approach towards predicting future human poses in real time using a single camera stream. We will discuss some of the challenges in making this pipeline work in real time as well as some of the shortcomings of the deep learning methods implemented.

Human detection - DEtection TRansformer (DETR)

In the human detection layer of our pipeline, our goal is to generate bounding boxes around detected humans in a given frame. Due to the realtime nature of our application, equal consdieration is given to inference time and mean average precision (mAP)
Comparison on Coco 2017 validation set:
| Model | Inference FPS | AP | AP 50 | AP 75 | AP S | AP M | AP L |
|---|---|---|---|---|---|---|---|
| Faster R-CNN+FPN | 26 | 42.0 | 62.1 | 45.5 | 26.6 | 45.4 | 53.4 |
| Deformable DETR | 19 | 43.8 | 62.6 | 47.7 | 26.4 | 47.1 | 58.0 |
| DETR | 28 | 42.0 | 62.4 | 44.2 | 20.5 | 45.8 | 61.1 |
Based on the above data, the models have comparable Mean Average Precision (mAP) but since DETR outperforms on inference speed, we choose the same for our implementation.
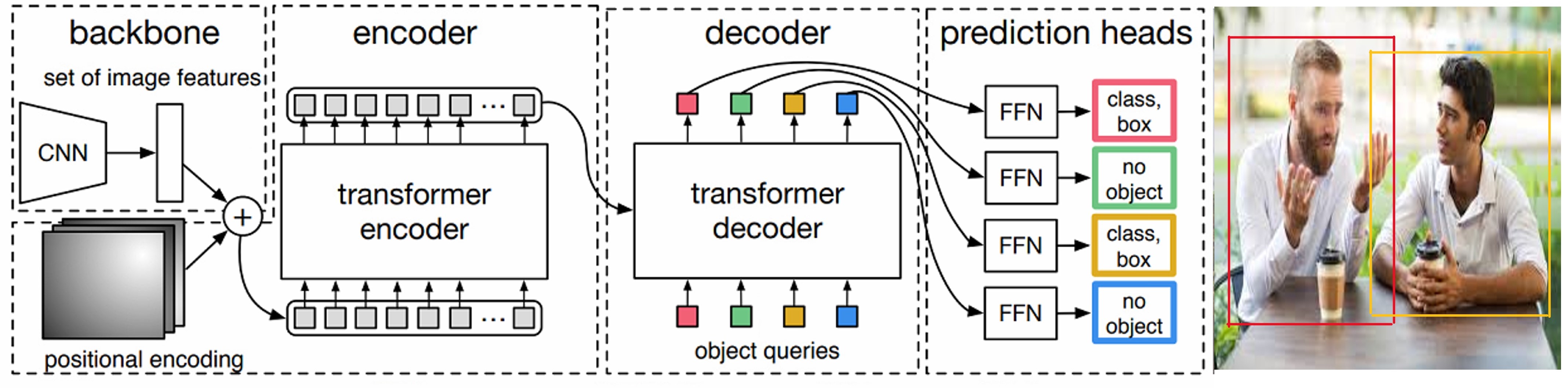
As shown in the above image, the main architecture of DETR can be broken down into a pipeline of three main components:
1. CNN backbone
The conventional CNN backbone is used to learn a 2D representation of an input image.
2. Encoder-decoder transformer
The flattened representation from the CNN is combined with positional encoding and feeded into a transformer encoder. The transformer decoder then takes a fixed number of learned encodings while attending to the encoder output.
3. Feed Forward Network (FFN)
The output of the decoder is passed to a shared feed forward network (FFN) that either predicts a detection or “no object” class.
2D pose detection - Video Pose Estimation via Neural Architectural Search (ViPNAS)

Human pose estimation is the process of detecting the pose of a person in a given image. For a given skeletal model, the goal is to detect keypoints (joints) of a human in a given image frame, followed by joining respective keypoints to generate a skeletal representation of the person. Again, we equally consider inference speed and accuracy tradeoff to select the best model for 2D pose detection.
| Model | Inference FPS | AP |
|---|---|---|
| ResNet | 29 | 0.72 |
| ShuffleNet | 63 | 0.6 |
| HRNet | 22 | 0.75 |
| ViPNAS + MobileNet | 54 | 0.7 |
For fast online video pose estimation, while achieving better trade off between accuracy and efficiency, we select ViPNAS for online pose estimation due to efficient pose estimation. The key to this architecture’s efficiency is allocation of different computational resources to different frames.
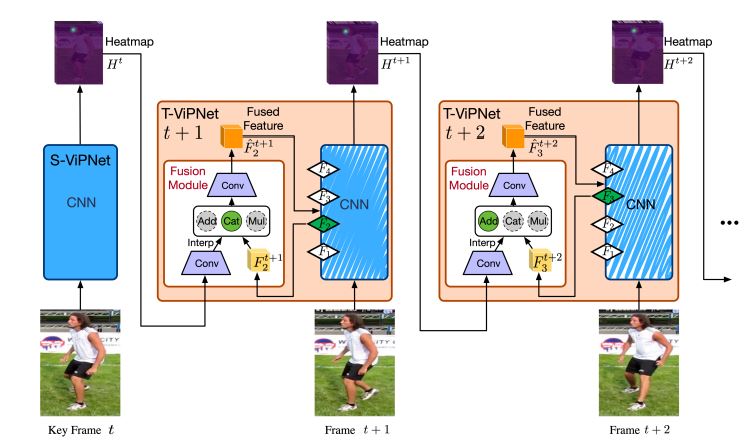
As shown above, the architecture can be decomposed into the following steps:
- Select a set of T + 1 frames in a video
- Out of the selected frames, select 1st frame as the key frame
- Apply spatial video pose estimation network (S-ViPNet) on the same to localize human poses.
- Use heat maps to encode joint locations as Gaussian peaks.
- For the non-key frames using temporal video pose estimation network (T-ViPNets):
- Some CNN layers are used for feature extraction.
- Fuse features of current frame with heat maps of last frame
- Pass fused features through remaining CNN layers to obtain heat maps.
The main analogy here is that poses in adjacent video frames are temporally correlated and thus light weight models like T-VipNets can reasonably estimate joint locations with guidance from previous frames.
2D to 3D pose lifting - VideoPose3D
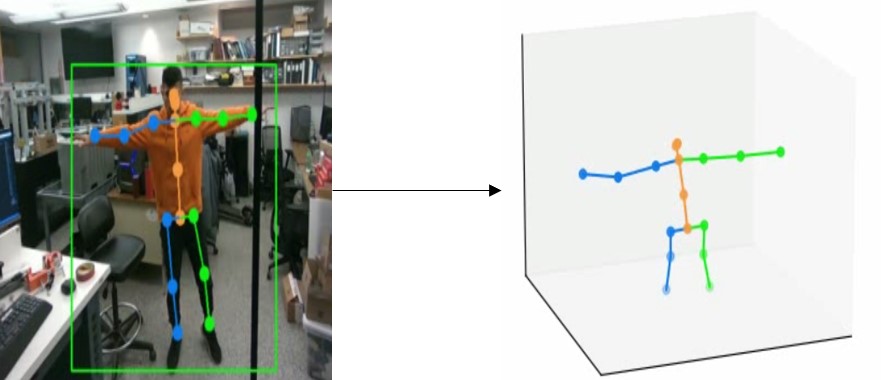
The goal of this layer is to infer the 3D poses given the 2D pose estimates from ViPNAS. VideoPose3D is a full convolutional architecture with residual connections and temporal convolutions as show below
The reason for picking temporal convolutions over RNNs is:
- Convolutional architecture offers precise control over temporal receptive fields, which the authors of the paper found important for 3D pose estimation.
- Convolutional models enable parallelization over batch and time dimension and also do not suffer from vanishing and exploding gradients.
To improve settings where labeled 3D ground-truth pose data is limited,a semi-supervised learning method is used as shown:
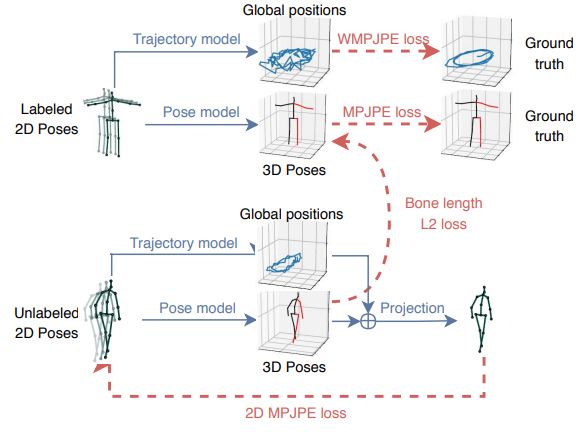
Essentially an unlabeled video with off the shelf 2D keypoint detector is used for a supervised loss function with back propagation loss term, and then the problem is setup as an auto encoding problem:
- Encoder: 2D joint coordinates -> 3D pose estimation
- Decoder 3D pose -> 2D joint coordinates
Lastly, since we require global position as well, 3D trajectory of the person is regressed by a very similar model compared to the pose model. ___
3D pose prediction
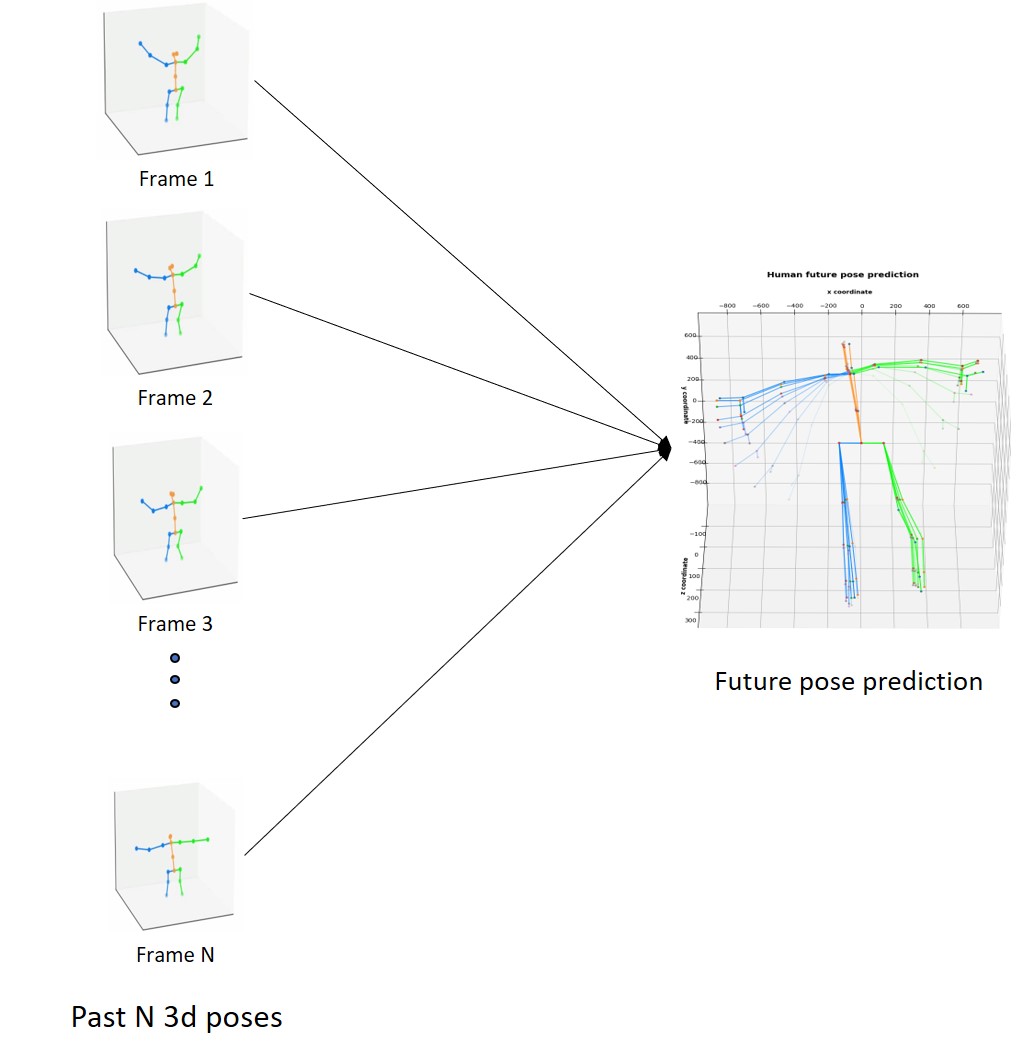
The goal of 3D pose prediction is given a past horizon of 3D joint poses, predict future joint poses over a given time horizon. For this task, we use the architecture called History Repeats Itself (HisRepItself) which tackles human motion prediction via motion attention.
For the purposes of this approach, we purely look at past frames over a certain horizon to predict future human poses over another horizon. The underlying hypothesis is since humans tend to repeat motion across long time periods, sub sequences in motion history can be discovered via motion attention.
This motion attention is then feeded in to the prediction model which consists of a Graph Convolutional Network (GCN) to capture the spatial relationship of the human skeletal joints.
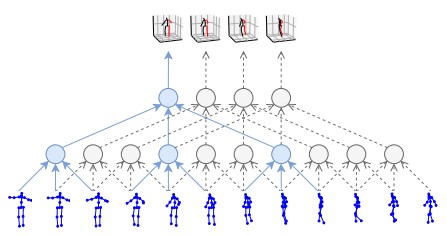
The visualization of the architecture is shown below:
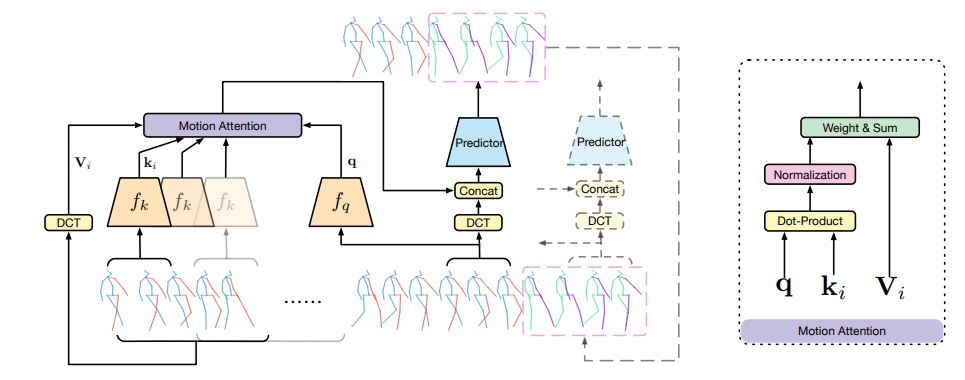
The past poses are shown as blue and red skeletons and predicted ones and green and purple. For a given time frame (M consecutive poses), the Discrete Cosine Transforms are weighed using the computed attention score, and the weighted sum are combined with DCT coefficients of last sub-sequence in the prediction layer to future predictions of human poses. ___
Inference results
Since the eventual goal of this approach is to leverage accurate human joint pose predictions in a human robot collaborative setting, we need to give equal importance to accuracy and inference speed. While we leave accuracy evaluations to test datasets, we analyze inference speeds for evaluating the application of this approach in a real time setting.
The given pipeline structured is implemented on a live video stream coming from a webcam and inference speeds for each subtask are calculated as shown below:
| DETR | ViPNAS | VideoPose3D | Motion attention | Overall fps | |
|---|---|---|---|---|---|
| Inference speed (fps) | 28 | 54 | 280 | 31 | 11 |
Fast inference speeds are crucial in a realtime human robot collaboration task due to which recently we have been seeing a rise in well engineered models like ViPNAS where heavy models are tied together with light weight models in a key frame - non-key frame approach in order make these models fast while not compromising on accuracy.
Challenges and key takeaways:
The key takeaway from this pipeline based approach for human motion prediction is interpretability of the sub tasks. By breaking down the goal into individual deep learning based models instead of learning end to end, we are able to identify and debug errors individually as well as the integration of domain knowledge in every sub task becomes easier.
Also due to the modular approach, it easy to replace certain parts of the model depending on the task at hand and retrain certain parts instead of going through the pain of retraining the entire model. Analyzing performance of individual components including attributes like inference speed makes it easier to highlight pain points of an approach and select and fine tune models accordingly, thus helping scale the architecture.
That being said, there are plenty of challenges that still need to be addressed in human motion prediction including some arising from the pipeline based approach:
- Robustness to missing joint positions and noisy data: It was noted that when using keypoint detections, often times there were missing joints due to the human being in different orientation or partially outside the frame. Also, when 2D to 3D pose lifting, often times the joint data would be noisy which led to overall bad human pose predictions. A few ways to make this approach more robust is by performing some kind of data imputation on missing joints data, training the predictor with augmented data that has noise as well as missing joints, thus making sure such cases are not our of distribution.
- Inference speed: As mentioned earlier, inference speed still remains a challenge in the application of this setup in a realtime collaborative setting. Around 11fps of overall inference speed is still not fast enough for high speed real time tasks and hence inference speed still remains a challenge.
- Error and uncertainty propagation: We highlighted that there was some noise and uncertainty associated with inferring the human joint pose data which also included errors where there was false detection, and thus throwing the predictor off in the downstream task of prediction. Also how uncertainties and errors from one block of the pipeline propagate to the other still remains an open question.
- Incorporating context based information: As we noted in the prediction part, we solely rely on past human poses to predict the future ones. In reality, this is not the case since a lot of times we use scene based contextual information to drive one’s motion.
- Incorporating joint constraints and fusing physics based models: Lastly, since this is a well studied dynamics problem, one possibility to improve this approach is to fuse physics based models as well as employ hard joint constraints in our model.
Conclusion
Thus we study a pipeline based approach towards human motion prediction from a stream of camera frames in the form of a video. We highlight the pros and cons of this approach as well as our reasoning for picking specific models for each individual subtask. We also highlight potential research avenues as well discuss what particular challenges we came across when experimenting with this approach in an actual setup.
References
[1] Zhu Xizhou, Su Weijie, Lu Lewei, Li Bin, Wang Xiaogang, and Dai Jifeng. 2020. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv:2010.04159. Retrieved from https://arxiv.org/abs/2010.04159.
[2] Xu L.-M., Guan Y.-D., Jin S., Liu W.-T., Qian C., Luo P., Ouyang W.-L., and Wang X.-G.. 2021. ViPNAS: Efficient video pose estimation via neural architecture search. In CVPR.
[3] Pavllo, Dario, et al. “3d human pose estimation in video with temporal convolutions and semi-supervised training.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
[4] Mao, Wei, Miaomiao Liu, and Mathieu Salzmann. “History repeats itself: Human motion prediction via motion attention.” European Conference on Computer Vision. Springer, Cham, 2020.
[5] Sengupta, Arindam, et al. “mm-Pose: Real-time human skeletal posture estimation using mmWave radars and CNNs.” IEEE Sensors Journal 20.17 (2020): 10032-10044.